The joy of working in an open community
📬 Get the future posts directly in your inbox:
During the last month or so, I’ve been struggling/stuck solving data processing scripts. Fortunately, working in geospatial sciences and with an open technology stack, the community is always there to help. In short, the process I was following was:
- Read the data.
- Process it with GeoPandas.
- Split the data to append it to two different tables in the database.
- Save the data in a Postgres database.
In theory, the process sounds quite simple. However, the challenge came from the size of the data -55 datasets of more than 20 million rows each- and the tame it took to upload the data into the database using geopandas, a Python 🐍 library to work with geodata. In my initial tests, for one file it ran for two days without finishing uploading the data. I optimized my code to run the analysis faster, but in the end, the bottleneck was moving the data into the database.
To solve the problem I tapped into the collective wisdom from open communities. The first step, as with most of the coding problems, was to turn to StackOverflow 🕵️. I found a couple of pointers on how to optimize the process, mostly when working with regular data tables. However, mines had geographical properties, thus making some of the suggestions not so easy to integrate into my workflow. After reading some technical blogs and getting, most of the time, similar answers and approaches I decided to ask in The Spatial Community slack. Within minutes I received a couple of answers pointing to possible specific solutions on how to modify my code and solve the roadblock. After some testing one of those solutions worked like a charm. I went from ♾ to less than a minute to upload the data.
I am very fortunate to be working on problems that are solved with open source technology, and that have a large welcoming community. Being able to interact with people around the world, that are working on similar topics, and that share their knowledge provides a great opportunity to keep growing and sharing knowledge.
For those of you with a technical background, here’s the solution I used, adapted from this blog post.
import psycopg2
import pandas as pd
import geopandas as gpd
from io import StringIO
from geoalchemy2 import Geometry, WKTElement
def gdf_to_df_geo(gdf):
"""Convert a GeoDataFrame into a DataFrame with the geometry
column as text
Args:
gdf (geopandas.GeoDataFrame): GeoDataFrame to be converted
Returns:
pandas.DataFrame: DataFrame with the geometry as text
"""
gdf['geom'] = gdf['geometry'].apply(lambda x:
WKTElement(x.wkt,
srid=4326))
# drop the geometry column as it is now duplicative
gdf.drop('geometry', 1, inplace=True)
gdf.rename(columns={'geom': 'geometry'}, inplace=True)
return gdf
def get_cursor():
"""Creates a SQL cursor
Returns:
pg_conn: psycopg2.connection
psycopg2 cursor: Cursor to interact with the database
"""
pg_conn = psycopg2.connect(database='NAME_DATABASE',
user='USER_DATABSE',
password='PASSWORD',
host='HOST_DATABASE')
cur = pg_conn.cursor()
return pg_conn, cur
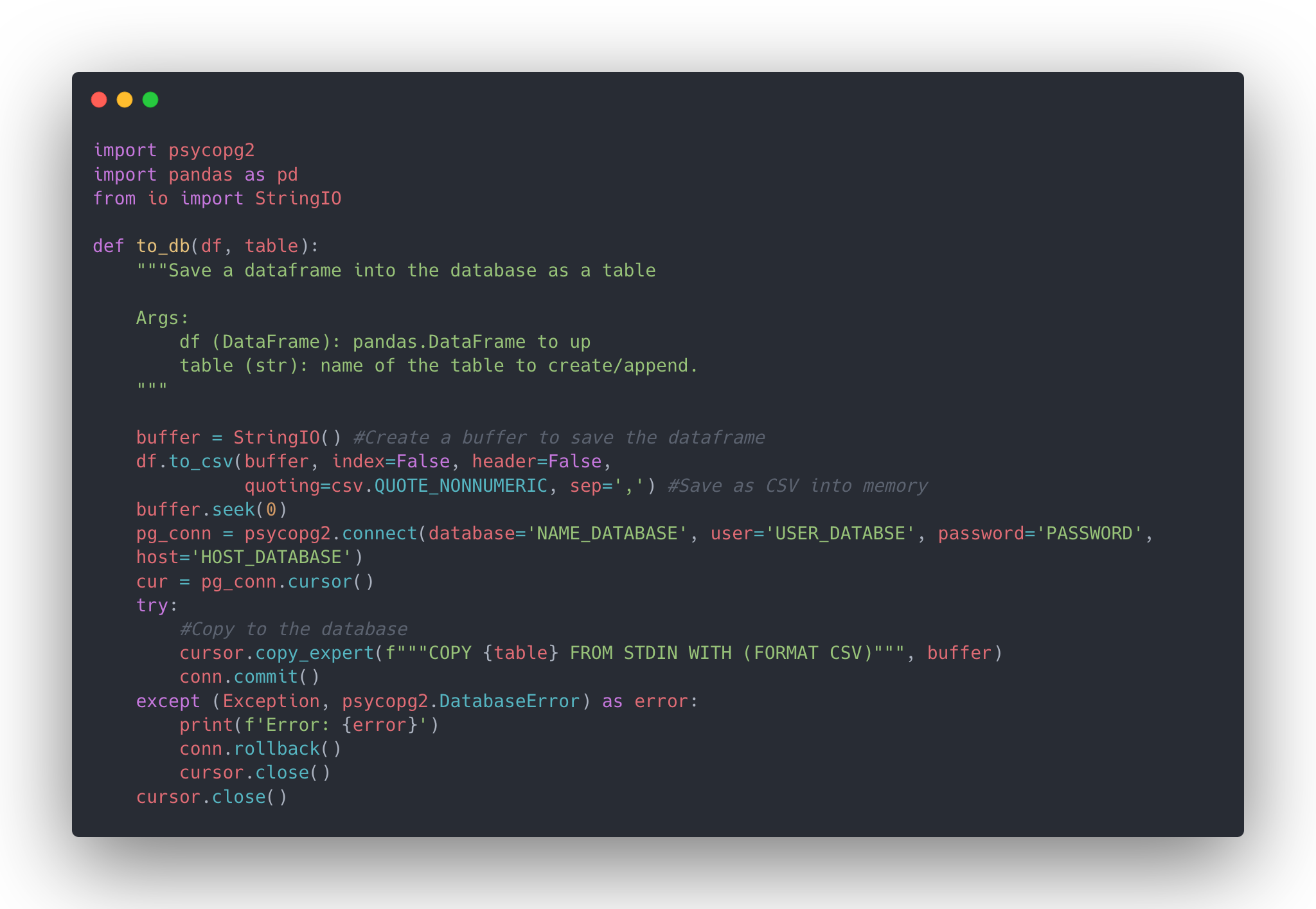
def to_db(df, table):
"""Save a dataframe into the database as a table
Args:
df (DataFrame): pandas.DataFrame to up
table (str): name of the table to create/append.
"""
buffer = StringIO() #Create a buffer to save the dataframe
df.to_csv(buffer,
index=False,
header=False,
quoting=csv.QUOTE_NONNUMERIC,
sep=',')
#Save as CSV into memory
buffer.seek(0)
conn = utils.connect()
cursor = conn.cursor()
try:
#Copy to the database
cursor.copy_expert(f"""COPY {table} FROM\
STDIN WITH (FORMAT CSV)""",
buffer)
conn.commit()
except (Exception, psycopg2.DatabaseError) as error:
print(f'Error: {error}')
conn.rollback()
cursor.close()
cursor.close()
# Read the file
gdf = gpd.read_file('my_file.geojson')
# Convert the GeoDataFrame to pandas.DataFrame
df = gdf_to_df_geo(gdf)
# Upload the dataframe to postgres
to_db(df, 'table_data')
📬 Get the blog posts directly in your inbox:
💬 Join the conversation:
Keep to conversation with a comment or reach out in my social networks.